REPORT GITHUB HUGGING FACE DEMO COMMUNITY
Introduction
In this blog, we introduce Sailor2, a community-driven initiative that brings cutting-edge multilingual language models to South-East Asia (SEA). Our research highlights a strong demand for models in the 8B and 20B parameter range for production use, alongside a 1B model for specialized applications, such as speculative decoding and research purposes. These models, released under the Apache 2.0 license, provide enhanced accessibility to advanced language technologies across the region.
Sailor2 builds upon the foundation of the awesome multilingual model Qwen2.5 (Learn more here) and is continuously pre-trained on ~500B tokens to support 15 languages better with a unified model. These languages include: English, Chinese, Burmese 🇲🇲, Cebuano🇵🇭, Ilocano🇵🇭, Indonesian🇮🇩, Javanese🇮🇩, Khmer🇰🇭, Lao🇱🇦, Malay🇲🇾, Sundanese🇮🇩, Tagalog🇵🇭, Thai🇹🇭, Vietnamese🇻🇳 and Waray🇵🇭.
By addressing the growing demand for diverse, robust, and accessible language models, Sailor2 seeks to serve the underserved in SEA areas with open, inclusive, and accessible multilingual LLMs.
Performance
We evaluate our models on several benchmarks, including IndoCutlure, TydiQA, Meta Thai MMLU, M3Exam, VMLU, Tatabahasa, FLORES-200, and XCOPA. The results of TydiQA, M3Exam, FLORES-200 and XCOPA are obtained from our previously released evaluation suite SailCompass. The results of Meta Thai MMLU are from the LightEval, and others are obtained from the evaluation scripts shared by the community members. More evaluation details will be shared in our upcoming paper.
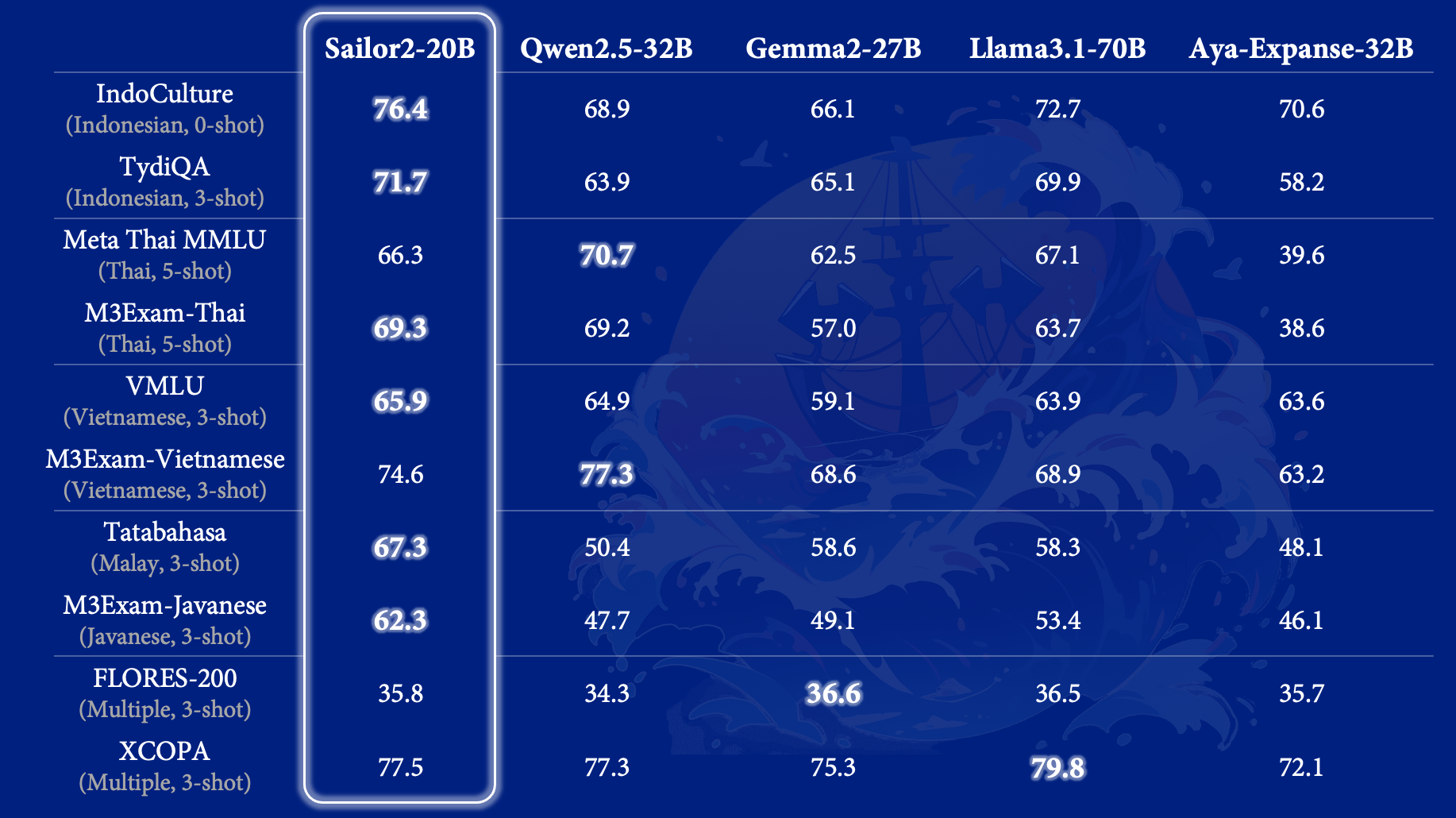
Compared to other advanced multilingual models like Qwen2.5-32B, Gemma2-27B, Llama3.1-70B, and Aya-Expanse-32B, our flagship 20B model demonstrates comparable or superior performance on languages such as Indonesian, Thai, Vietnamese, Malay, and Javanese. It excels in machine translation tasks and multilingual reasoning, including benchmarks like XCOPA. Most notably, due to the inclusive design of the Sailor2 models, our 20B model significantly outperforms others in extremely low-resource languages, such as M3Exam-Javanese, achieving an improvement of +14.6 over Qwen2.5-32B.
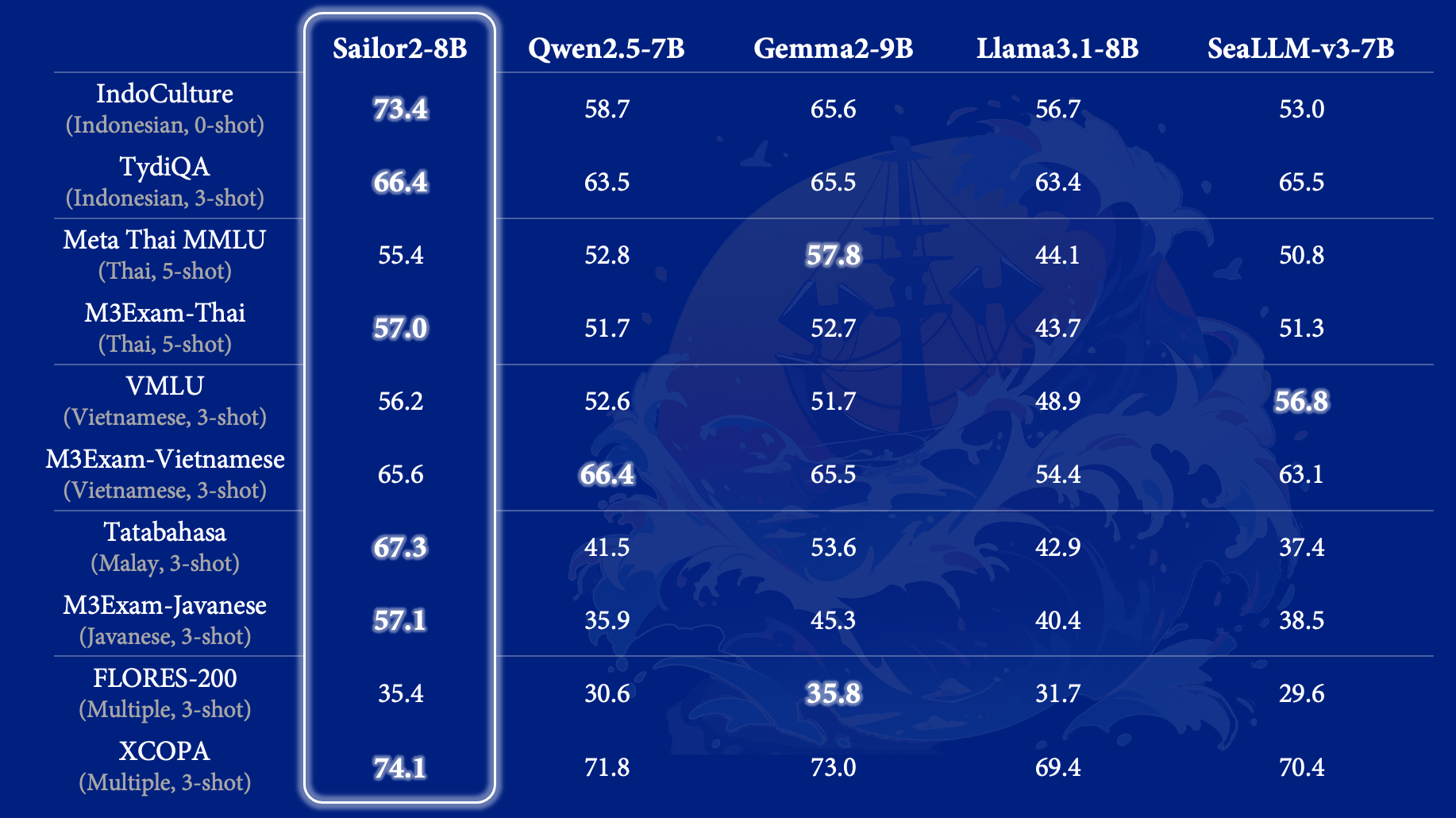
The Sailor2-8B model stands out as the best multilingual model for SEA languages in the < 10B category, outperforming all other open-access language models in general.
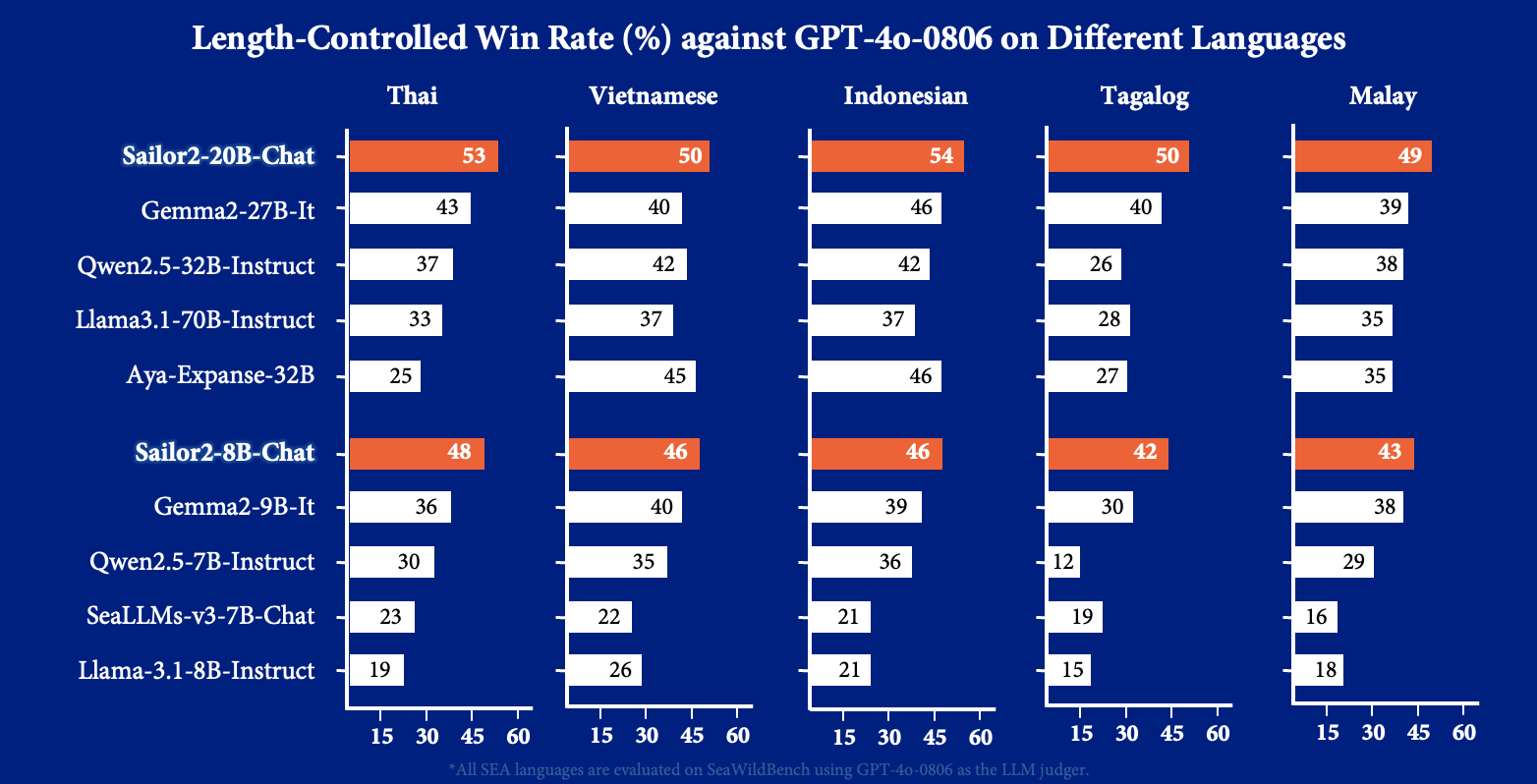
We also evaluated our chat models using the translated WildBench, Sea-WildBench, a challenging benchmark for chat models. As shown, the win rate of Sailor2-20B-Chat against GPT-4o-0806 on SeaWildBench is nearly 50%, demonstrating that Sailor2-20B-Chat performs at a GPT-4o level for local chat scenarios.
Continual Pre-training
Our data is primarily sourced from web HTML documents and publicly available PDF files, covering a diverse range of languages, including English, Chinese, and the above mentioned SEA languages. For English and Chinese datasets, we predominantly utilize existing datasets shared by the community. For SEA languages, we collect the data independently and in collaboration with partners.
The dataset for SEA languages continual pre-training, sourcing documents from a variety of materials containing up-to-date knowledge until the end of 2023. To ensure high data quality, we apply several deduplication and cleaning techniques across each source. After comprehensive deduplication and cleaning, the total available dataset is as follows, along with its corresponding disk usage (ordered by disk size):
| Language | Disk size |
|---|---|
| Vietnamese | 1.9T |
| Indonesian | 1.3T |
| Thai | 242G |
| Malay | 44G |
| Burmese | 25.8G |
| Tagalog | 17.5G |
| Khmer | 6.9G |
| Cebuano | 2.1G |
| Lao | 1.9G |
| Javanese | 1.2G |
| Waray | 0.8G |
| Sundanese | 0.75G |
| Ilocano | 0.2G |
Model Expansion
The Sailor2 model comes in three sizes, 1B, 8B, and 20B, which are expanded from the Qwen2.5 base models of 0.5B, 7B, and 14B, respectively. The decision was made to perform model expansion prior to continual pre-training in order to mitigate the potential for forgetting of English and Chinese language capabilities, while also enhancing the model’s capacity for further improvements in SEA languages.
In practice, the approach draws inspiration from the method proposed by LlamaPro, leveraging a block-expansion mechanism in the original Qwen2.5 model. This approach significantly enhances the model’s performance in SEA languages while maintaining stable capabilities in English and Chinese. By utilizing the strategy, the newly introduced layers are able to store the additional SEA knowledge from the continually pre-trained tokens, rather than overwriting the existing linguistic information of the other languages.
Data Cleaning and Deduplication
We leveraged sailcraft for comprehensive data processing, employing multiple deduplication techniques including near and exact deduplication, heuristics-based cleaning, URL deduplication, and frequent line removal. During URL deduplication, we prioritized documents with more content, effectively reducing total tokens by nearly 50%. As for the frequent line removal, following the Llama3 approach, we removed lines appearing more than 5 times in 10M document buckets, successfully eliminating nearly 5% of total tokens—most of which were determined to be meaningless content.
Two-Stage Training
We adopt the two-stage pre-training approach introduced in the MiniCPM paper. In the first stage, we use comprehensive datasets and a relatively high learning rate (1e-4), while in the second stage, we focus on high-quality tokens with a smaller learning rate (1e-5).
Drawing from the forgetting rules outlined in the Sailor paper, we introduce high-resource languages during the first stage (such as English, Chinese, Vietnamese, Indonesian, Thai, Malay, Burmese, Tagalog, and Khmer). In the second stage, we transition to both high-resource and low-resource languages (including Cebuano, Lao, Javanese, Waray, Sundanese, and Ilocano). This two-stage approach allows automatic data mixture in the first stage, while allowing us to incorporate high-quality tokens from low-resource languages in the second stage without rescheduling the mixing ratios.
Stage 1: Balanced Data Mixture
In the stage 1 of our continual pre-training, we select a subset of languages that could provide sufficiently enough tokens for data mixture optimization. We employed RegMix to optimize the data mixture, with the primary objective of maximizing the log sum across all languages considered in stage 1.
Unlike our previous practices in Sailor that used 0.5B models as proxy models for data mixture, we follow RegMix to utilize 1M models as our proxy model, even for the scenario of continual pre-training. Our underlying assumption was that if a model can be trained over an extended period, the converged or equivalent data mixture should remain relatively consistent.
After conducting 1,000 runs of data mixture optimization using 1M models, we observed a subtle shift from the original token distribution. Notably, the optimized data mixture resulted in upsampling languages like Khmer, Malay, Burmese, Thai, and Tagalog, while simultaneously downsampling Indonesian and Vietnamese. The final data mixture of Stage 1 is as below (tokens counted in the tokenizer of Qwen2.5):
| Language | Effective Tokens |
|---|---|
| Vietnamese | 102B |
| Indonesian | 94B |
| Thai | 92B |
| English | 51B |
| Chinese | 50B |
| Burmese | 23.5B |
| Malay | 21B |
| Tagalog | 10B |
| Khmer | 6.5B |
| Stage 1 (Total) | 450B |
Stage 2: Synthetic Data to Retrieve High-Quality Tokens
In stage 2, we lower the learning rate to 1e-5 (1/10 of the original learning rate), and take 20% of the stage 1 dataset to make sure the model still behaves well on the original distribution. As for the remaining 80% training budget, we allocate them to high-quality SEA tokens, where all low-resource languages are added, and the token distribution of high-resource languages is maintained as similar to the stage 1.
To address challenges in selecting high-quality datasets for low-resource languages, we use NLLB 3.3B to translate high-quality English documents into local languages. A fast-text classifier is then trained for each language to identify high-quality subsets, using 10K positive and 10K negative examples. Positive examples are machine-translated from English high-quality datasets, while negative examples are sampled from the raw dataset from the web. After training, we rank the dataset by classifier scores and select the top results (between 10% to 20%, according to the requirement of the ratio in data mixture) as the high-quality subset for the stage 2 training. In addition, we also added some English instruction tuning datasets and some datasets contributed by the Sailor2 community.
| Language | Effective Tokens |
|---|---|
| Stage 1 | 10B |
| English Instruction Tuning Dataset | 2.5B |
| Vietnamese (High-Quality) | 10.9B |
| Indonesian (High-Quality) | 12.8B |
| Thai (High-Quality) | 13.9B |
| Burmese (High-Quality) | 2.8B |
| Malay (High-Quality) | 1.3B |
| Tagalog (High-Quality) | 2.2B |
| Khmer (High-Quality) | 0.9B |
| Waray (High-Quality) | 0.02B |
| Ilocano (High-Quality) | 0.05B |
| Javanese (High-Quality) | 0.17B |
| Lao (High-Quality) | 0.33B |
| Cebuano (High-Quality) | 0.30B |
| Sundanese (High-Quality) | 0.09B |
| Stage 2 (Total) | 60B |
Post-Training
We conduct both the supervised fine-tuning and preference tuning based on the above Sailor2 base models.
Supervised Fine-tuning
Drawing inspiration from OpenCoder, we have implemented a strategic two-stage Supervised Fine-Tuning (SFT) process that tackles common training challenges head-on. In the first stage, we cast a wide net, training the model on the entire dataset for a single epoch using large batch sizes. This initial exposure helps establish broad coverage across different SEA languages and domains.
The second stage switches to a more focused approach with smaller batch sizes and multiple training epochs on carefully curated, high-quality data that is balanced across domains and languages. Our quality selection process relies on two key metrics: perplexity from the Sailor2 base model (PPL) and reward scores. High-perplexity examples represent cases where the model is less confident – precisely the areas where it needs the most improvement. While high perplexity identifies learning opportunities, high reward scores ensure we’re learning from exemplary content.
To prevent the model from overfitting to similar examples, we employ embedding-based similarity checks. This additional filter ensures our training data remains diverse and representative, leading to a more robust and versatile model. This refined approach to fine-tuning has proven effective in producing models that are both broadly capable and specifically strong in high-priority domains.
Preference Tuning
Our preference tuning consists of two stages, training with off-policy responses generated by Llama-3-8B-Instruct and training with on-policy responses generated by Sailor2 suite. In the off-policy training stage, we first translate the preference dataset, UF-Llama3, into SEA languages. Low-quality translations are then filtered based on perplexity scores provided by the Sailor2-8B base. The resulting off-policy dataset is a mixture of SEA languages and English. In the on-policy training stage, we utilize the prompts from the off-policy dataset. For each prompt, responses are generated using the model trained on the off-policy data. These responses are rated by the open-source reward model, Skywork-Reward-Gemma-2-27B. The highest-rated response is selected as the chosen response and the lowest-rated response is selected as the rejected response. Additionally, we employ a language-consistency verifier to detect and correct cases where the input language differs from the output language, except for the translation task.
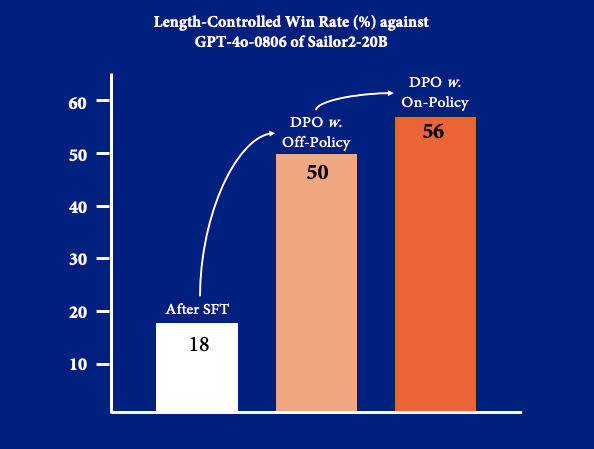
Due to the absence of a high-quality reward model for PPO-based algorithms, we explore different direct alignment algorithms, such as DPO and its variants. We conducted extensive hyperparameter tuning and ablation studies to ensure the model performance on the development evaluations. All experiments were conducted with the training framework, Oat, which enables large-scale and flexible training. Below, we summarize our key findings:
- DPO achieves comparable performance to its length-normalized variants (e.g. Length-normalized DPO and SimPO) while demonstrating better training stability.
- Off-policy training serves as an effective initialization for on-policy training.
- On-policy training further improves the model performance across various benchmarks.
- The dataset processed using the language-consistency verifier provides a consistent performance gain.
Develop with Sailor2
The code of Sailor2 has been in the latest Hugging face transformers and we advise you to install transformers==4.46.3.
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda" # the device to load the model
model = AutoModelForCausalLM.from_pretrained("sail/Sailor2-20B", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("sail/Sailor2-20B")
input_message = "Model bahasa adalah model probabilistik"
# The given Indonesian input translates to 'A language model is a probabilistic model of.'
model_inputs = tokenizer([input_message], return_tensors="pt").to(device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=64
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
Limited Free API Service
We also offer a limited free API service for Sailor2-20B-Chat in collaboration with Float16.cloud. You can access the API using the following details:
curl -X POST "https://api.float16.cloud/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sailor2" \
-d '{
"model": "sailor2-20b-chat",
"messages": [
{
"role": "system",
"content": "You are an AI assistant named Sailor2, created by Sea AI Lab. As an AI assistant, you can answer questions in English, Chinese, and Southeast Asian languages such as Burmese, Cebuano, Ilocano, Indonesian, Javanese, Khmer, Lao, Malay, Sundanese, Tagalog, Thai, Vietnamese, and Waray. Your responses should be friendly, unbiased, informative, detailed, and faithful."
},
{
"role": "user",
"content": "สวัสดี"
}
]
}'
Acknowledgement

This is a huge effort from the collaboration among the community, along with researchers from Sea AI Lab, SCB10X, WiseSight, HuggingFace, and the whole Sailor2 community.
Citation
@article{sailor2report,
title = {Sailor2: Sailing in South-East Asia with Inclusive Multilingual LLM},
author = {Longxu Dou and Qian Liu and Fan Zhou and Changyu Chen and Zili Wang and Ziqi Jin and Zichen Liu and Tongyao Zhu and Cunxiao Du and Penghui Yang and Haonan Wang and Jiaheng Liu and Yongchi Zhao and Xiachong Feng and Xin Mao and Man Tsung Yeung and Kunat Pipatanakul and Fajri Koto and Min Si Thu and Hynek Kydl{\'\i}{\v{c}}ek and Zeyi Liu and Qunshu Lin and Sittipong Sripaisarnmongkol and Kridtaphad Sae-Khow and Nirattisai Thongchim and Taechawat Konkaew and Narong Borijindargoon and Anh Dao and Matichon Maneegard and Phakphum Artkaew and Zheng-Xin Yong and Quan Nguyen and Wannaphong Phatthiyaphaibun and Hoang H. Tran and Mike Zhang and Shiqi Chen and Tianyu Pang and Chao Du and Xinyi Wan and Wei Lu and Min Lin},
journal={arXiv preprint arXiv:2502.12982},
year = {2025}
}